ANTIBOTS - PART II - What is AST Manipulation, What is Regex, Why Would I Prefer One Over The Other?
We got to the point I’ve been waiting for: AST Manipulation and Regex.
First, what is regex? Regex is short for “regular expression” which basically specifies a pattern. Antibots are javascript, and javascript is just code. Code is made up of characters, so the whole script you could say is a loooooooooong string. Regex works on just that… Strings! You can match anything you’d like… aaaaaaand anything you don’t like, here’s an example what I’m talking about:
function solution(){
let key = 'secret_key';
return key;
}
Here’s, in code, what a function in javascript looks like. Let’s say our function solution was always just like that in code and we could find the code. We could create a regular expression (or actually 2) to find the key, great news!
Let’s see what these would look like:
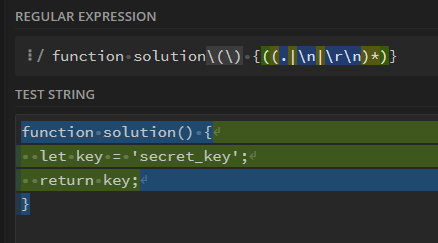
Making use of https://regex101.com we found a Regex that would suffice what we search for (at least the first part):
/function solution\(\) {((.|\n|\r\n)*)}/gm
Our first matching group would be this one:
let key = 'secret_key';
return key;
Now we can do the same for this string as well and get our secret key, you see where this is going..
Let's see how someone that creates these antibots would trick our code pretty easily!
/*
function solution(){
let key = 'fake_key';
return key;
}
*/
function solution() {
let key = 'secret_key';
return key;
}
Just like that, our first regex would have 2 matches this time, and the way we built it was to get the first match, so we'd end up with the fake key instead of the real one!
Yes, sure someone could come up and say how we could edit our regex and make it even more complex to find the right key by detecting if it is a comment. That's not the point.
The point is, regexes become really long and hard, and hard to maintain, and scale, and ugly. It’s just not the right approach for if the antibot changes much. (even tho it’s pretty fast I gotta admit, much faster than what I’m about to show you)
That’s where AST comes into play!
AST is the short form of Abstract Syntax Tree. Javascript is basically a programming language, it has to be interpreted by the interpreter.
When it gets interpreted, the interpreter also has a parser that transforms all that javascript into an AST, so what we are going to do is “tokenize” our script and transform it from there.
To understand tokenization better let’s take a look at english. When we speak we combine WORDS together into SENTENCES. Words can be of different types NOUN, ADJECTIVE, ADVERB. So we can tokenize each word and specify what type it is. There’s more to english, you can break down sentences into clauses and have a main and a secondary clause, it’s a whole process!
Javascript is just the same, let’s take for example a variable declaration (I’ll be using https://astexplorer.net for seeing the nodes inside the AST, I shall recommend you use it, too, since it’s quite a powerful tool! I’ll also be using the BABEL suite for parsing the script into AST, traversing the AST and generating the final script back from AST):
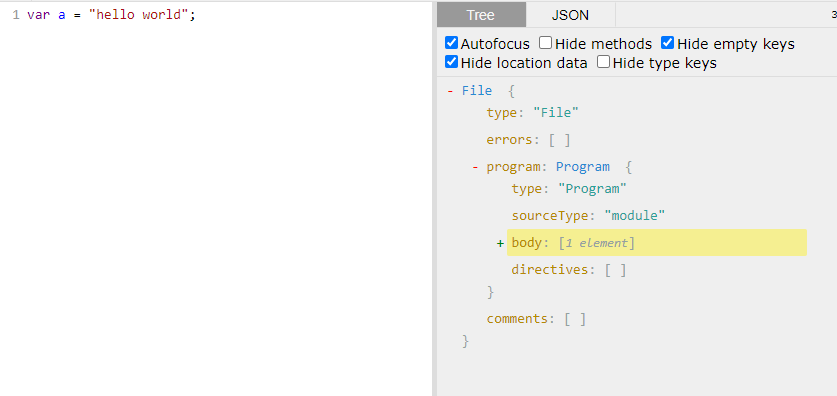
Everything starts with the File object. Inside this object we got the Program object, inside of which we got the Body array, which is an array that is composed of all the nodes inside the script. At the moment we only have 1 node and that’s the variable declaration on the left side!
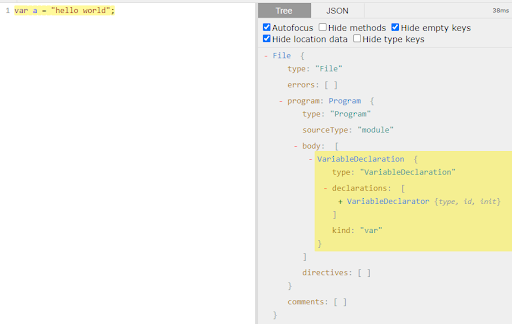
Opening up the body array and expanding the first node we can see it is of type “VariableDeclaration” and contains an array of declarations composed of only 1 declaration, a variable declaration! Let’s open that up and see what we’ll learn about it…
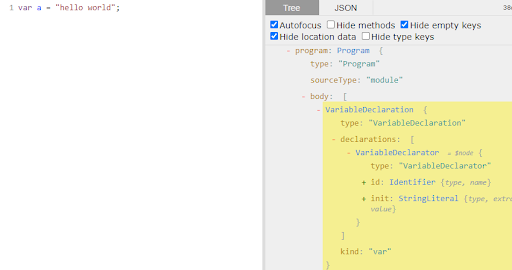
As we can see, the VariableDeclarator node is composed of 2 other nodes: its id (the variable’s name) and the value it holds.
We can also see that the variable name is a node of type Identifier while the value it holds is a string literal (Peep that it’s inside quotes)
A list of all the types can be found at: https://babeljs.io/docs/en/babel-types which will help us when doing transformations because we’ll have to create nodes to replace other nodes!
So the basics of it is that, that is what AST is all about, tokenization, based on that, we’ll be able to traverse the AST, find specific nodes by their types and also filter them by the type of nodes they contain and what not, endless possibilities! And you’ll see it will actually be much easier to comprehend than regex, though this will come at the cost of time (parsing and traversing is pretty costly).